About This Demo
This demo showcases a Visual Retrieval-Augmented Generation (RAG) application over PDFs using ColPali embeddings in Vespa, built entirely in Python, using FastHTML. The code is fully open source.
Resources
- Vespa Blog: How we built this demo
- Notebook to set up Vespa application and feed dataset
- Web App (FastHTML) Code
- Vespa Blog: Scaling ColPali to Billions
- Vespa Blog: Retrieval with Vision Language Models
Architecture Overview
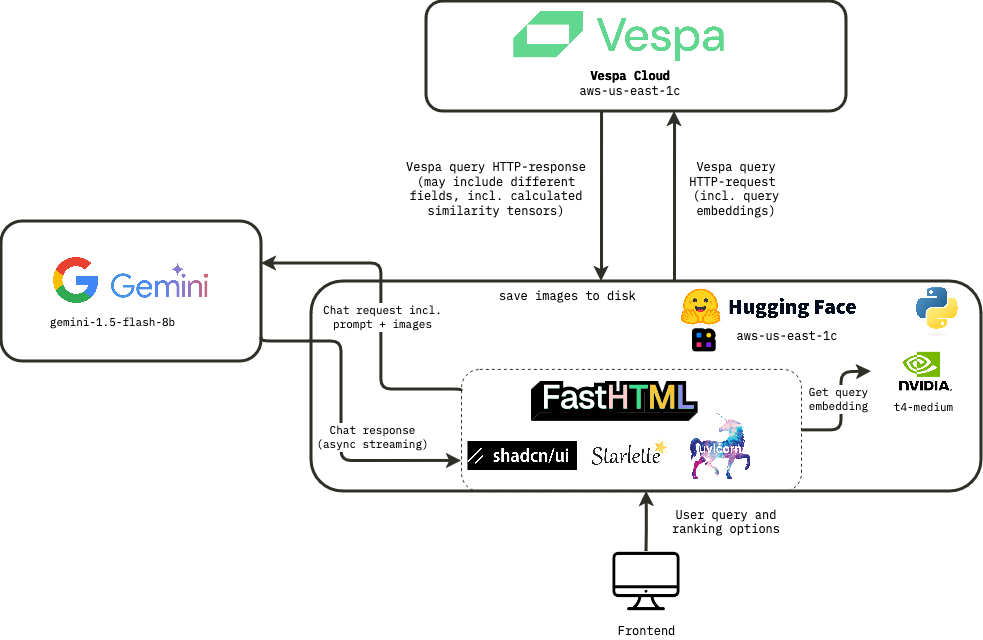
- Vespa Application: Vespa Application that handles indexing, search, ranking and queries, leveraging features like phased ranking and multivector MaxSim calculations.
- Frontend: Built with FastHTML, offering a professional and responsive user interface without the complexity of separate frontend frameworks.
- Backend: Also built with FastHTML. Handles query embedding inference using ColPali, serves static files, and is responsible for orchestrating interactions between Vespa and the frontend.
- Gemini API: VLM for the AI response, providing responses based on the top results from Vespa.
- Fast and Responsive: Optimized for quick loading times, with phased content delivery to display essential information immediately while loading detailed data in the background.
- Similarity Maps: Provides visual highlights of the most relevant parts of a page in response to a query, enhancing interpretability.
- Type-Ahead Suggestions: Offers query suggestions to assist users in formulating effective searches.
User Experience Highlights
Dataset
The dataset used in this demo is retrieved from reports published by the Norwegian Government Pension Fund Global. It contains 6,992 pages from 116 PDF reports (2000–2024). The information is often presented in visual formats, making it an ideal dataset for visual retrieval applications.